

DFS(depth first search)와 BFS(breadth first search)는 트리와 그래프를 탐색할때 사용하는 알고리즘이다. 여기서는 그래프 탐색에 대해 알아보자.
- graph
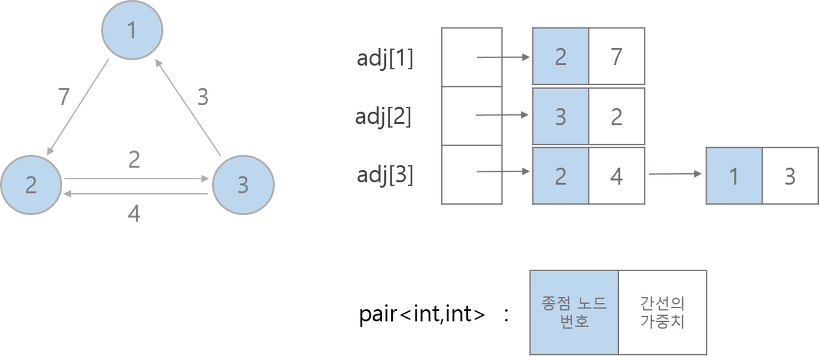
그래프는 정점(vertex, v)과 간선(edge, e)로 이루어진 자료구조로, 현실에서도 많이 사용되기에 꼭 알아두어야 한다. 대표적으로 지도, sns 서비스의 친구 관계등이 있다. 또한 뱡향(directed), 무방향(undirected), 가중치 그래프 등 여러 종류의 그래프가 있는데, 가장 간단한 무방향 그래프를 구현할 것이다. 그래프를 구현하는 방법으로 2 차원 배열을 이용하거나 연결리스트를 활용할 수 있는데, 우리는 연결 리스트로 구현해보자.
class Graph {
constructor() {
this.adjacencyList = {};
}
addVertex(v) {
// 정점 추가
if (this.adjacencyList[v]) return 'vertex already exist!'; // 만약 이미 존재하는 정점일경우 종료
this.adjacencyList[v] = [];
}
addEdge(v1, v2) {
// 간선 추가
this.adjacencyList[v1].push(v2);
this.adjacencyList[v2].push(v1);
}
removeEdge(v1, v2) {
// 간선 삭제
this.adjacencyList[v1] = this.adjacencyList[v1].filter(v => v !== v2);
this.adjacencyList[v2] = this.adjacencyList[v2].filter(v => v !== v1);
}
removeVertex(v) {
// 정점 삭제
this.adjacencyList[v].forEach(adjV => this.removeEdge(v, adjV)); // 삭제할 정점과 연결된 간선들 모두 삭제
this.adjacencyList[v] = null;
}
}
- DFS
한국어로는 ‘깊이 우선 탐색’인데, 깊이를 우선한다는게 무슨 말일까? 말 그대로, 같은 레벨의 다른 노드들 보다 아랫 레벨 노드를 우선적으로 방문한다는 의미이다.
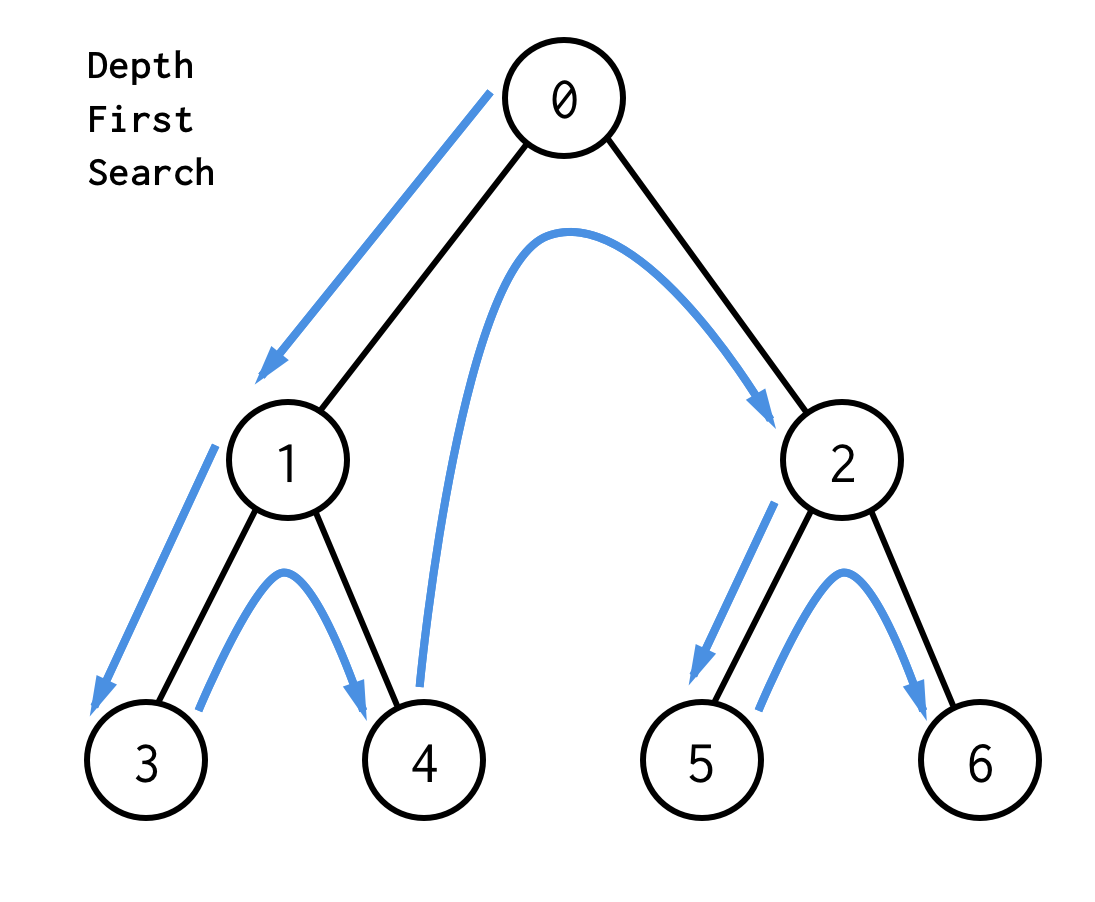
그래프의 경우 시작 노드에서의 거리가 멀 수록 트리에서 낮은 레벨의 노드에 해당한다고 생각하면 된다. DFS 는 stack 을 이용하여 탐색하는데, 방문한 노드들을 하나씩 stack 에 넣은 뒤, 더이상 내려갈 레벨이 없으면 스택에서 꺼내서 윗 레벨의 노드로 돌아가는 방식이다.
코드를 보자.
class Graph {
constructor() {
this.adjacencyList = {};
}
// ...
// ...
// 재귀알고리즘으로 구현한 dfs. 재귀 호출 자체가 콜 스택을 사용하기 때문에 따로 스택을 구현할 필요가 없다.
dfsRecursive(startV) {
let result = []; // 방문순서를 저장할 배열
let visited = {}; // 이미 방문한 정점을 기록하는 객체
const dfs = v => {
visited[v] = true;
result.push(v);
this.adjacencyList[v].forEach(nearV => {
if (!visited[nearV]) dfs(nearV);
});
};
dfs(startV);
return result;
}
// 반복알고리즘으로 구현한 dfs. 스택을 직접 구현한다.
dfsIterative(startV) {
let result = [];
let visited = { [startV]: true };
let stack = [startV]; // 스택은 배열로 구현
while (stack.length) {
// 스택에 정점이 남아있는 동안 반복
const current = stack.pop(); // 스택에서 하나를 가져온다.
result.push(current);
this.adjacencyList[current].forEach(nearV => {
if (!visited[nearV]) {
stack.push(nearV);
visited[nearV] = true;
}
});
}
}
}
- BFS
한국어로는 너비 우선 탐색으로, 같은 레벨의 노드드를 모두 탐색한 뒤 다음 레벨로 진행하는 방식이다.
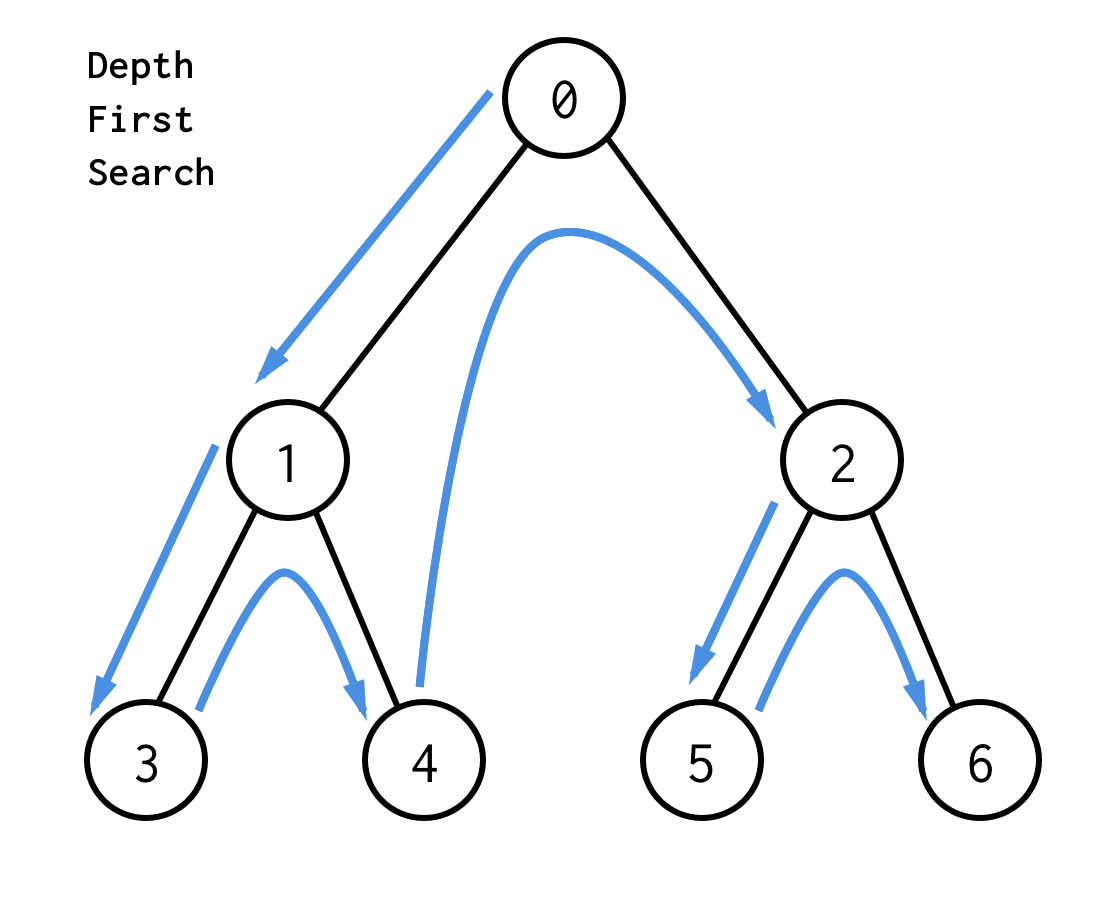
BFS 는 큐를 이용해 탐색한다. 큐의 특성상 먼저 들어간 노드가 먼저 나오게 되므로, 자식 노드보다 형제 노드에 먼저 접근하게 된다. 코드를 보자.
class Graph {
constructor() {
this.adjacencyList = [];
}
//...
//...
bfs(startV) {
const result = [];
const visited = { [startV]: true };
const queue = [startV];
while (queue.length) {
const current = queue.shift();
result.push(current);
this.adjacencyList[current].forEach(nearV => {
if (!visited[nearV]) {
queue.push(nearV);
visited[nearV] = true;
}
});
}
}
}
이렇게 큐와 스택을 이용한 두가지 탐색을 알아보았다.